CAS-JUC的基石
0.preface
在JDK 5之前Java语言是靠synchronized关键字保证同步的,这会导致有锁
锁机制存在以下问题:
(1)在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题。
(2)一个线程持有锁会导致其它所有需要此锁的线程挂起。
(3)如果一个优先级高的线程等待一个优先级低的线程释放锁会导致优先级倒置,引起性能风险。
volatile是不错的机制,但是volatile不能保证原子性。因此对于同步最终还是要回到锁机制上来。
独占锁是一种悲观锁,synchronized就是一种独占锁,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。而另一个更加有效的锁就是乐观锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁用到的机制就是CAS,Compare and Swap。
1. CAS
CAS,Compare And Swap,即比较并交换。Doug lea大神在同步组件中大量使用CAS技术鬼斧神工地实现了Java多线程的并发操作。整个AQS同步组件、Atomic原子类操作等等都是以CAS实现的,甚至ConcurrentHashMap在1.8的版本中也调整为了CAS+Synchronized。毫不夸张的说CAS是整个JUC的基石。
当前的处理器基本都支持 CAS,只不过不同的厂家的实现不一样罢了。CAS 有三个操作数:内存值 V、旧的预期值 A、要修改的值 B。
当且仅当 V 的值等于 A 时,CAS通过原子方式用新值B来更新V的值(“比较+更新”整体是一个原子操作),否则不会执行任何操作。一般情况下,“更新”是一个不断重试的操作。
如果我们不用 CAS,那么代码大致是这样的:
1 | public int i = 1; |
当然这段代码在并发下是肯定有问题的,有可能线程 1 运行到了第 5 行正准备运行第 7 行,线程 2 运行了,把 i 修改为 10,线程切换回去,线程1由于先前已经满足第 5 行的 if 了,所以导致两个线程同时修改了变量 i。
解决办法也很简单,给 compareAndSwapInt 方法加锁同步就行了,这样,compareAndSwapInt 方法就变成了一个原子操作。CAS 也是一样的道理
CAS 也是通过 Unsafe 实现的,看下 Unsafe 下的三个方法:
1 | public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x); |
- o:目标Java变量引用。
- offset:目标Java变量中的目标属性的偏移地址。
- expected:目标Java变量中的目标属性的期望的当前值。
- x:目标Java变量中的目标属性的目标更新值。
JDK8中基于CAS扩展出来的方法有getAndAddInt、getAndAddLong、getAndSetInt、getAndSetLong、getAndSetObject,它们的作用都是:通过CAS设置新的值,返回旧的值。
CAS是一条CPU的原子指令(cmpxchg指令),不会造成所谓的数据不一致问题,Unsafe提供的CAS方法(如compareAndSwapXXX)底层实现即为CPU指令cmpxchg。
下面就以AtomicInteger为例来分析CAS的实现。
1 | public class AtomicInteger extends Number implements java.io.Serializable { |
关于这段代码中出现的几个成员属性:
- Unsafe是 CAS 的核心类,前面已经讲过了。
- valueOffset 表示的是变量值在内存中的偏移地址,因为 Unsafe 就是根据内存偏移地址获取数据的原值的。
- value 是用 volatile 修饰的,这是非常关键的,保证多线程环境下看见的是同一个
下面找一个方法 getAndIncrement 来研究一下 AtomicInteger 是如何实现的,比如我们常用的 addAndGet 方法:
1 | public final int addAndGet(int delta) { |
CPU提供了两种方法来实现多处理器的原子操作:总线加锁或者缓存加锁。
总线加锁:总线加锁就是就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占使用共享内存。但是这种处理方式显得有点儿霸道,不厚道,他把CPU和内存之间的通信锁住了,在锁定期间,其他处理器都不能其他内存地址的数据,其开销有点儿大。所以就有了缓存加锁。
缓存加锁:其实针对于上面那种情况我们只需要保证在同一时刻对某个内存地址的操作是原子性的即可。缓存加锁就是缓存在内存区域的数据如果在加锁期间,当它执行锁操作写回内存时,处理器不在输出LOCK#信号,而是修改内部的内存地址,利用缓存一致性协议来保证原子性。缓存一致性机制可以保证同一个内存区域的数据仅能被一个处理器修改,也就是说当CPU1修改缓存行中的i时使用缓存锁定,那么CPU2就不能同时缓存了i的缓存行。
2. CAS缺陷
CAS虽然高效地解决了原子操作,但是还是存在一些缺陷的,主要表现在三个方法:循环时间太长、只能保证一个共享变量原子操作、ABA问题。
循环时间太长
如果CAS一直不成功呢?这种情况绝对有可能发生,如果自旋CAS长时间地不成功,则会给CPU带来非常大的开销。在JUC中有些地方就限制了CAS自旋的次数,例如BlockingQueue的SynchronousQueue。
只能保证一个共享变量原子操作
看了CAS的实现就知道这只能针对一个共享变量,如果是多个共享变量就只能使用锁了,当然如果你有办法把多个变量整成一个变量,利用CAS也不错。例如读写锁中state的高地位
ABA问题
CAS需要检查操作值有没有发生改变,如果没有发生改变则更新。但是存在这样一种情况:如果一个值原来是A,变成了B,然后又变成了A,那么在CAS检查的时候会发现没有改变,但是实质上它已经发生了改变,这就是所谓的ABA问题。对于ABA问题其解决方案是加上版本号,即在每个变量都加上一个版本号,每次改变时加1,即A —> B —> A,变成1A —> 2B —> 3A。
用一个例子来阐述ABA问题所带来的影响。
有如下链表
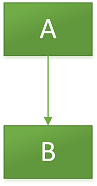
假如我们想要把A替换为B,也就是compareAndSet(A,B)。线程1执行A替换为B的操作,线程2主要:A 、B出栈,然后C、A入栈。最终该链表如下:
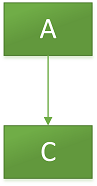
完成后线程1发现仍然是A,那么compareAndSet(A,B)成功,但是这时会存在一个问题就是B.next = null,compareAndSet(A,B)后,会导致C丢失,该栈仅有一个B元素,平白无故把C给丢失了。
CAS的ABA隐患问题,解决方案则是版本号,Java提供了AtomicStampedReference来解决。AtomicStampedReference通过包装[E,Integer]的元组来对对象标记版本戳stamp,从而避免ABA问题。
1 | public boolean compareAndSet(V expectedReference, |
compareAndSet有四个参数,分别表示:预期引用、更新后的引用、预期标志、更新后的标志。 解预期的引用 == 当前引用,预期的标识 == 当前标识,如果更新后的引用和标志和当前的引用和标志相等则直接返回true,否则通过Pair生成一个新的pair对象与当前pair CAS替换。Pair为AtomicStampedReference的内部类,主要用于记录引用和版本戳信息(标识),定义如下:
1 | private static class Pair<T> { |
Pair记录着对象的引用和版本戳,版本戳为int型,保持自增。同时Pair是一个不可变对象,其所有属性全部定义为final,对外提供一个of方法,该方法返回一个新建的Pari对象。pair对象定义为volatile,保证多线程环境下的可见性。在AtomicStampedReference中,大多方法都是通过调用Pair的of方法来产生一个新的Pair对象
下面我们将通过一个例子可以可以看到AtomicStampedReference和AtomicInteger的区别。我们定义两个线程,线程1负责将100 —> 110 —> 100,线程2执行 100 —>120,看两者之间的区别。
1 | public class Test { |
输出
1 | AtomicInteger:true |
运行结果充分展示了AtomicInteger的ABA问题和AtomicStampedReference解决ABA问题。
不过目前来说这个类比较”鸡肋”,因为大部分情况下 ABA 问题并不会影响程序并发的正确性,如果需要解决 ABA 问题,使用传统的互斥同步可能回避原子类更加高效。
3. CAS与synchronized
简单的来说 CAS 适用于写比较少的情况下(多读场景,冲突一般较少),synchronized 适用于写比较多的情况下(多写场景,冲突一般较多)
- 对于资源竞争较少(线程冲突较轻)的情况,使用 Synchronized 同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗 cpu 资源;而 CAS 基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。